A map of sauna days in more than 14 provinces is coming.
Recently, "going out for five minutes and sweating for two hours" has become a true portrayal of southern friends, and a wave of large-scale sauna weather is affecting the southern region. In the next three days (July 28th to 30th), stewing will continue. Over 14 provinces, autonomous regions and municipalities will "steam sauna" together, and Guangdong, Fujian and other places will experience the "high-temperature brand sauna", which will make you sweat like a bath in minutes. China Weather Network launched a map of sauna days all over the country to see if you are the one to be steamed.
These places are comparable to "saunas" outdoors.
Mid-autumn has arrived. All the year round, this festival is the hottest time in most parts of China, especially in the south, where the humidity is obviously higher than that in the head. Apart from heat, the biggest feeling is boredom.
According to the map of sauna days in China launched by China Weather Network, more than 14 provinces, autonomous regions and municipalities in China will "steam sauna" together in three days from now to experience sweating. Among them, there is still a wide range of high temperature weather in Jiangnan and South China. The highest temperature in Zhejiang, Fujian, Jiangxi, Hunan and other places can reach 37 to 40 C, the local temperature is above 40 C, and the humidity is generally above 60%. The hot and humid steam is constantly supplied. Although there is no high temperature in some places in southern North China and Huanghuai, the humidity will increase after the rain, and it will become a place that must be "steamed" in the later stage.
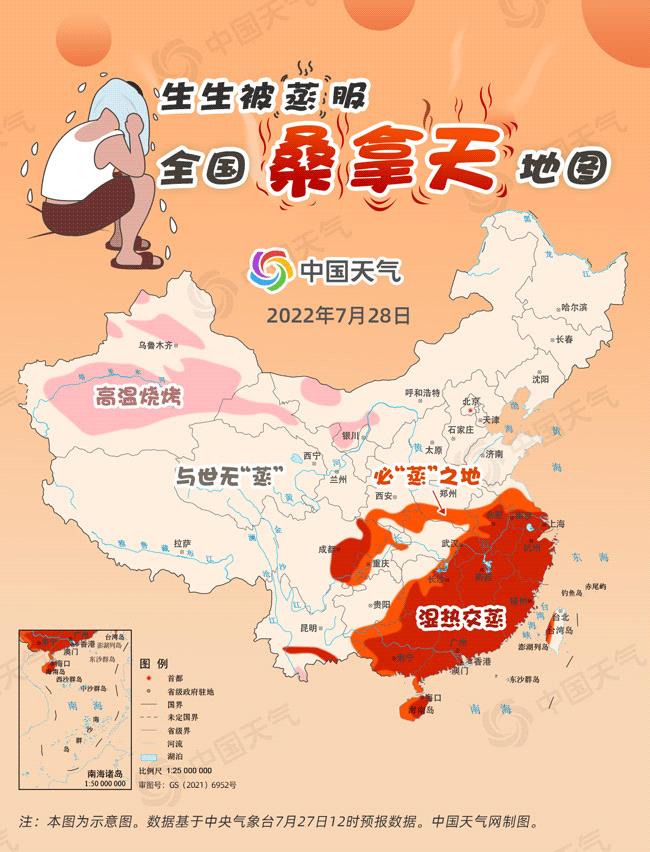
Today, southern Jiangsu, southern Anhui, Shanghai, Zhejiang, most of Jiangxi, central and southern Hunan, Sichuan Basin, Fujian, Guangdong, Guangxi and eastern Hainan will be steaming in hot and humid conditions, especially in eastern Jiangnan and central South China, where the highest temperature is generally above 37℃, and the average relative humidity is basically over 60%, making it comparable to a "sauna room" outdoors and being "steamed" immediately after going out. In addition to the above-mentioned areas, Hubei, southern Henan, southwestern Shaanxi, eastern Sichuan, central Jiangsu and other places, although there is no high temperature weather, are still sultry and must be "steamed".
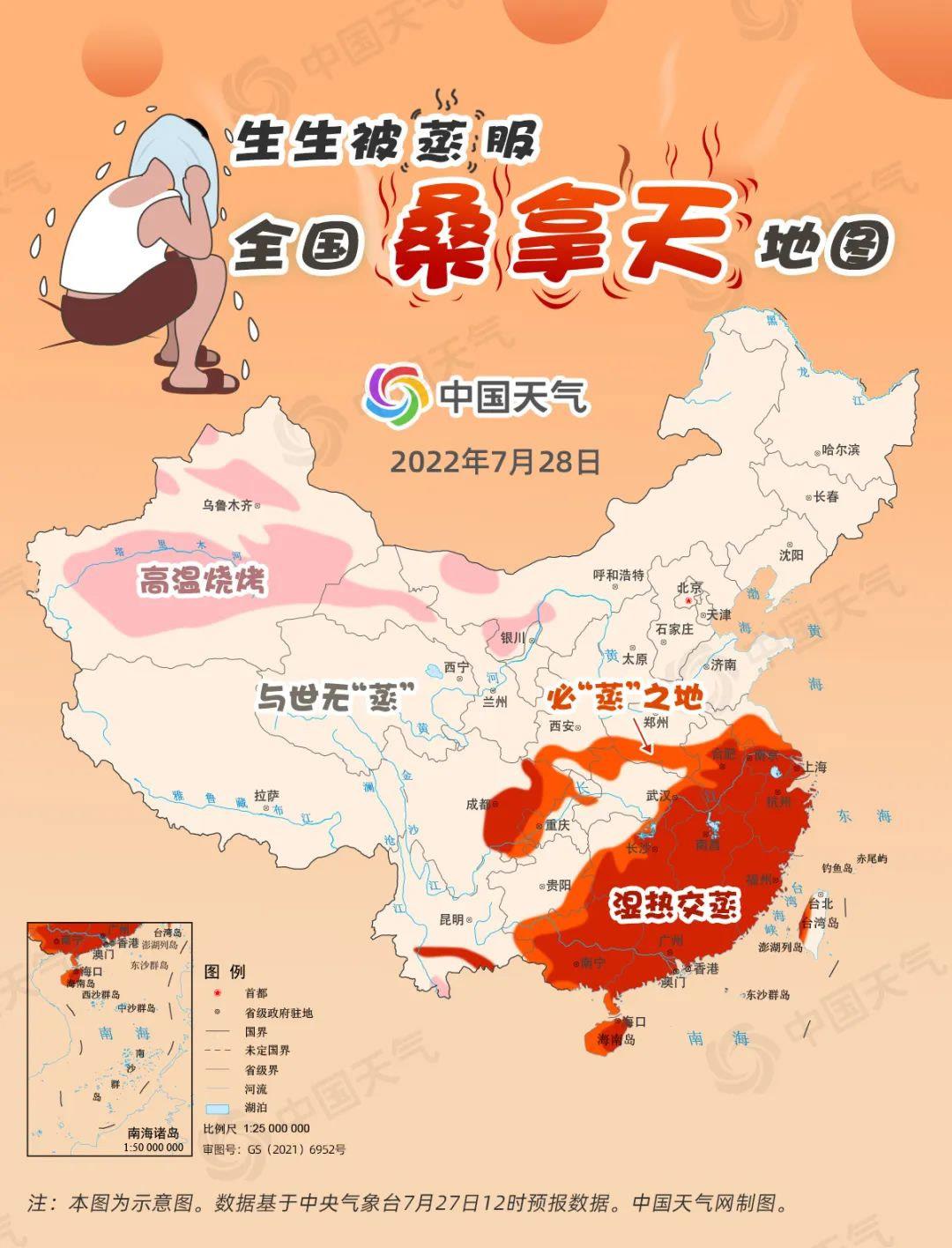
Tomorrow, the range of high temperature weather in the south will be reduced, but the highest temperature in Jiangxi, southern Hunan, southern Anhui, eastern Sichuan, Guangdong, most of Guangxi and other places is basically above 35℃. Although the wind is strong in some areas, the "sauna feeling" is still outstanding, and it is difficult to escape the hot and humid steam. Outside the range of hot and humid steaming, places where there is no high temperature, such as central Jiangsu, central Anhui and eastern Hubei, will also have the feeling of stewing and steaming, which is a place that must be "steamed".
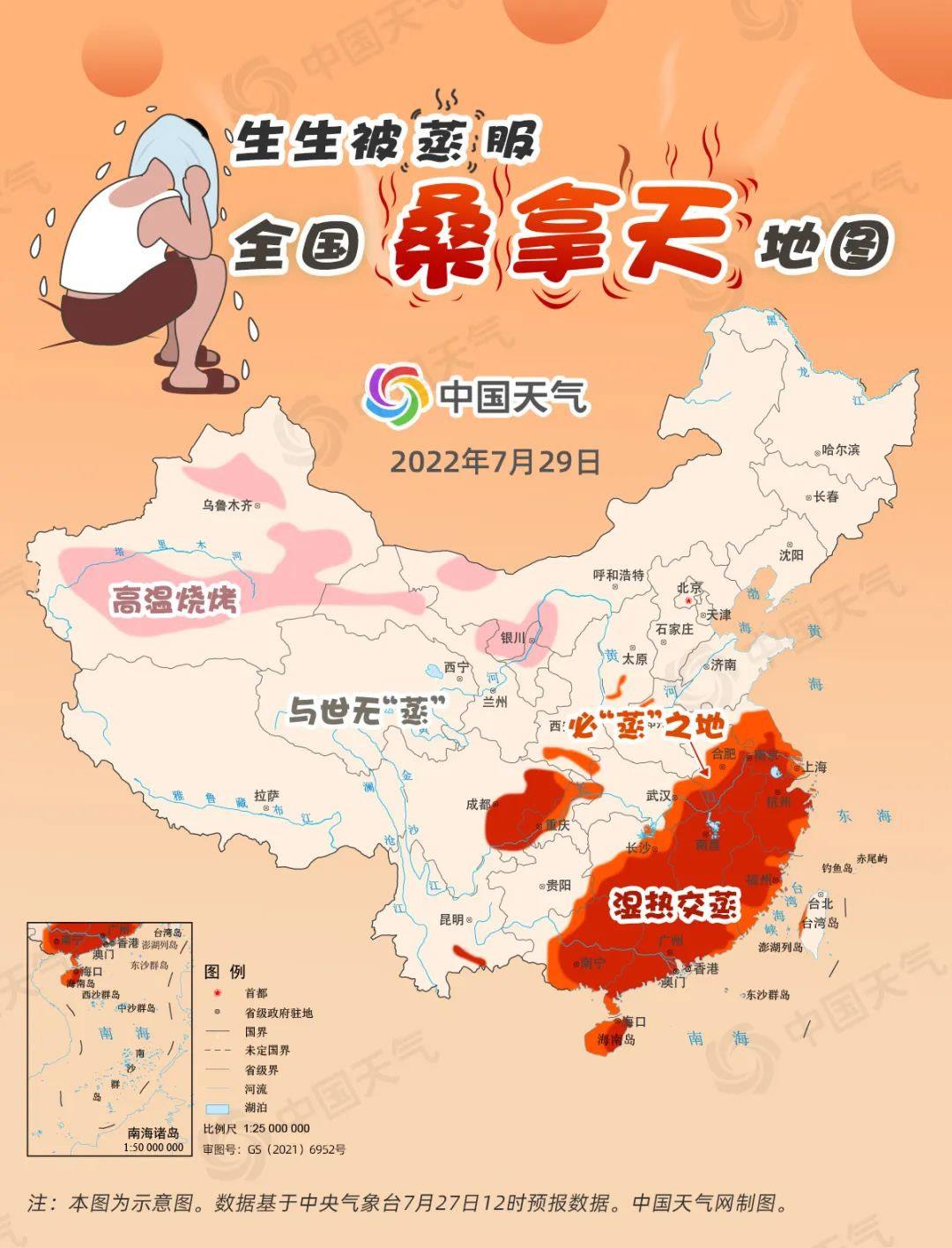
The day after tomorrow, the scope of "the land that must be steamed" will be further expanded to the north. Except for Jiangnan and most parts of South China, the humidity in central and southern Hebei, northwestern Shandong and northeastern Henan will increase after the rain, and the highest temperature will basically be above 32℃, which will give you the same "sauna feeling" as in the south.
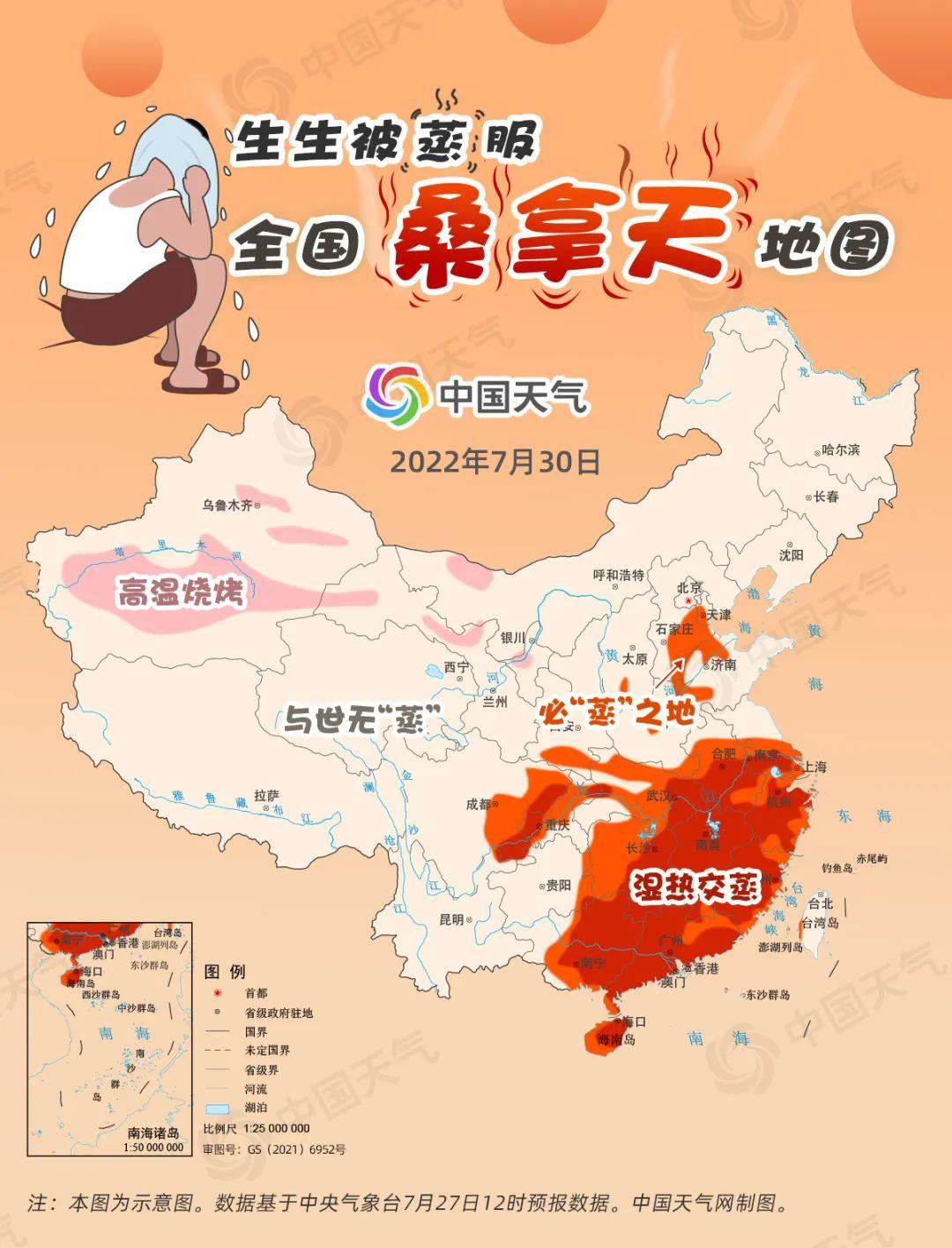
At the same time, although there is no sauna weather in the northwest, there is also high temperature weather. Under the sun, the road becomes "teppanyaki" every second, and it is necessary to do a good job of sun protection when going out to burn Jio.
The most enviable places are most of Northeast China, central and eastern Inner Mongolia, Qinghai, Tibet, western Sichuan and Guizhou. There is no sauna day or high temperature day, and it is in a state of "steaming".
Compared with the north, the south is more prone to sauna weather. From 1991 to 2020, big data show that the areas with frequent sauna days in China are concentrated in the south, among which Hainan, Guangdong and Fujian are the areas with the most frequent sauna days, with an average annual sauna days of more than 45 days. This is because in summer, the main body of the western Pacific subtropical high often controls most of the south of the Yangtze River and South China, and the temperature in downward flow increases, which leads to the hot and stuffy area. At the same time, the summer monsoon continuously transports water vapor, which increases the air humidity in this area. The high-humidity weather conditions also have a certain relationship with the geographical environment in the above areas. The middle and lower reaches of the Yangtze River are criss-crossed, with abundant water sources and strong evaporation. South China, on the other hand, is near the sea and has a high humidity.
Get "three more and two less" summer guide
Every summer, sauna days are the most difficult. In this kind of weather, high temperature and high humidity are combined, which makes it difficult to breathe. Why is the sauna day so hard? According to Wang Weiyue, generally speaking, people cool down by sweating in hot weather, and sweat can take away the heat generated by the human body in time. However, in sauna days, due to the high humidity and low wind speed, the evaporation rate of sweat is greatly slowed down, and clothes can be soaked after going out for a few minutes, feeling sticky all over.
Due to the imbalance between heat production and heat dissipation, people are prone to heatstroke in sauna days, especially the following types of people, which need special care. For example, people who drink less water and have underdeveloped sweat glands are not easy to sweat and suffer from heatstroke in sauna days; For people who are stressed and irritable, hot and humid weather will easily affect their hypothalamic ability to regulate emotions, leading to palpitation and chest tightness; People with poor cardiopulmonary function are prone to cardiovascular diseases in high temperature and high humidity environment.

How to prevent heatstroke and cool down in sauna days? This "three more and two less" summer guide needs to be known. First, drink plenty of water and replenish electrolytes lost due to sweating in time; Second, more ventilation, often staying in air-conditioned rooms is prone to dizziness, nasal congestion and other symptoms, so it is necessary to open the window in time to maintain indoor and outdoor air circulation; The third is to rest more, keep enough sleep for 6 to 8 hours, and increase the lunch break for about half an hour if possible to enhance immunity. We should also do two things less. First, we should reduce travel during the afternoon when the temperature is high. Second, if there are symptoms of heatstroke such as dizziness and nausea, we should rest immediately and drink cold water to cool down. If the condition is serious, we should go to the hospital immediately. Master the above guidelines to help you spend the summer safely.
Source: CCTV news client























